
Nathanaël Carraz Rakotonirina
Hello there 👋! I am a PhD student at Universitat Pompeu Fabra, supervised by Marco Baroni. I am interested in Robustness, Controllability and Interpretability of Large Language Models. I am currently working on the ALiEN project.
Selected publications
2024
-
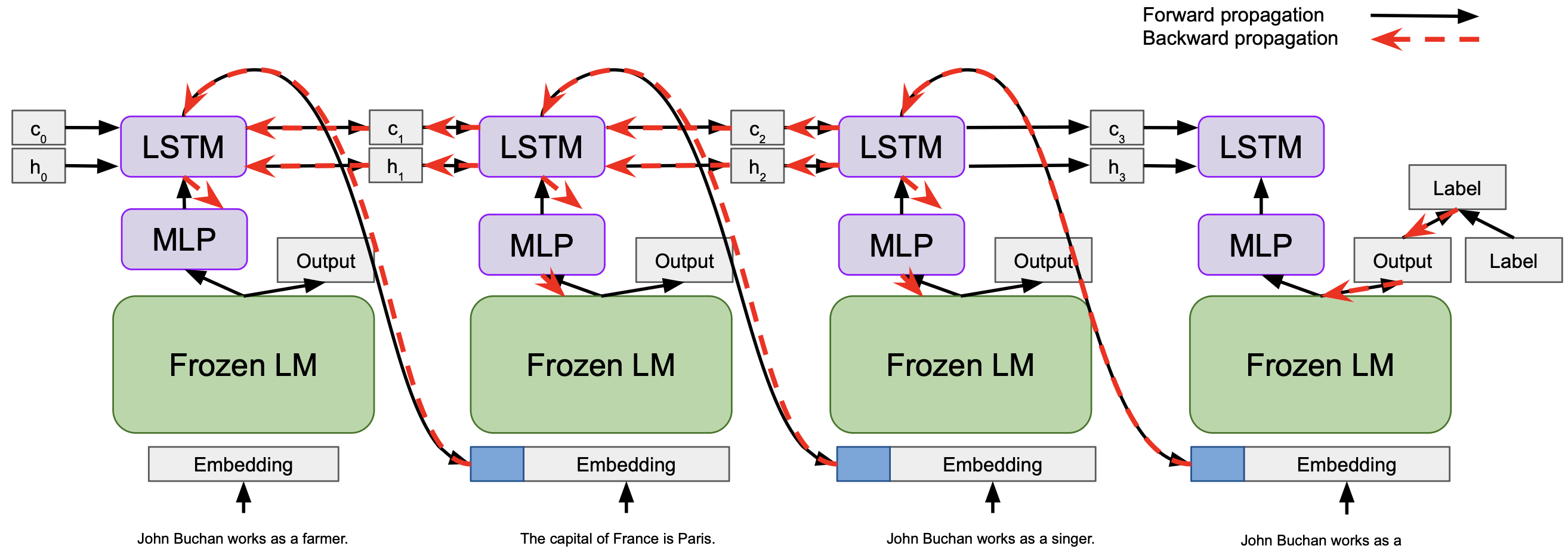 MemoryPrompt: A Light Wrapper to Improve Context Tracking in Pre-trained Language ModelsNathanaël Carraz Rakotonirina, and Marco BaroniLREC-COLING, 2024
MemoryPrompt: A Light Wrapper to Improve Context Tracking in Pre-trained Language ModelsNathanaël Carraz Rakotonirina, and Marco BaroniLREC-COLING, 2024Transformer-based language models (LMs) track contextual information through large, hard-coded input windows. We introduce MemoryPrompt, a leaner approach in which the LM is complemented by a small auxiliary recurrent network that passes information to the LM by prefixing its regular input with a sequence of vectors, akin to soft prompts, without requiring LM finetuning. Tested on a task designed to probe a LM’s ability to keep track of multiple fact updates, a MemoryPrompt-augmented LM outperforms much larger LMs that have access to the full input history. We also test MemoryPrompt on a long-distance dialogue dataset, where its performance is comparable to that of a model conditioned on the entire conversation history. In both experiments we also observe that, unlike full-finetuning approaches, MemoryPrompt does not suffer from catastrophic forgetting when adapted to new tasks, thus not disrupting the generalist capabilities of the underlying LM.

2023
- Optimizing with low budgets: A comparison on the black-box optimization benchmarking suite and openai gymElena Raponi, Nathanaël Carraz Rakotonirina, Jérémy Rapin, Carola Doerr, and Olivier TeytaudIEEE Transactions on Evolutionary Computation, 2023
The growing ubiquity of machine learning (ML) has led it to enter various areas of computer science, including black-box optimization (BBO). Recent research is particularly concerned with Bayesian optimization (BO). BO-based algorithms are popular in the ML community, as they are used for hyperparameter optimization and more generally for algorithm configuration. However, their efficiency decreases as the dimensionality of the problem and the budget of evaluations increase. Meanwhile, derivative-free optimization methods have evolved independently in the optimization community. Therefore, we urge to understand whether cross-fertilization is possible between the two communities, ML and BBO, i.e., whether algorithms that are heavily used in ML also work well in BBO and vice versa. Comparative experiments often involve rather small benchmarks and show visible problems in the experimental setup, such as poor initialization of baselines, overfitting due to problem-specific setting of hyperparameters, and low statistical significance. With this paper, we update and extend a comparative study presented by Hutter et al. in 2013. We compare BBO tools for ML with more classical heuristics, first on the well-known BBOB benchmark suite from the COCO environment and then on Direct Policy Search for OpenAI Gym, a reinforcement learning benchmark. Our results confirm that BO-based optimizers perform well on both benchmarks when budgets are limited, albeit with a higher computational cost, while they are often outperformed by algorithms from other families when the evaluation budget becomes larger. We also show that some algorithms from the BBO community perform surprisingly well on ML tasks.
-
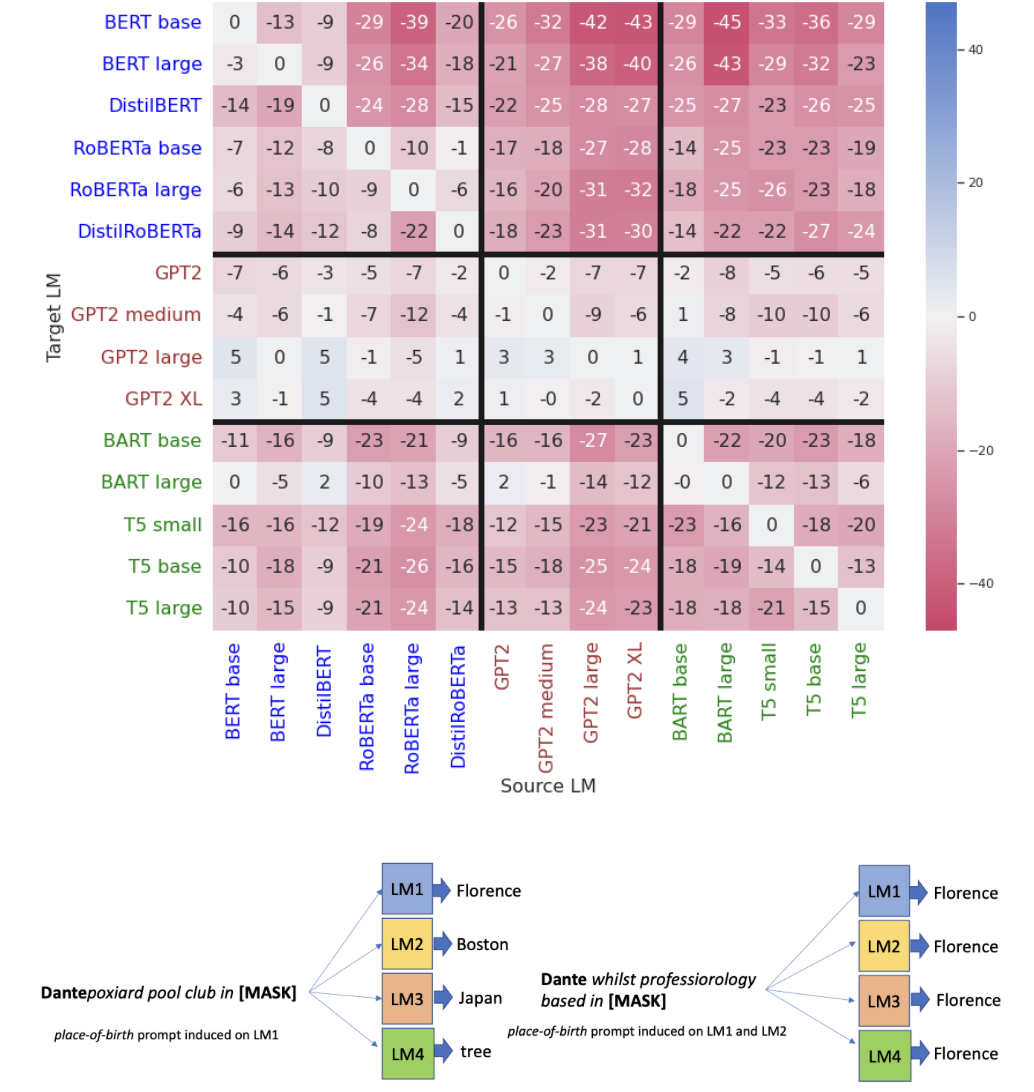 Can discrete information extraction prompts generalize across language models?Nathanaël Carraz Rakotonirina, Roberto Dessı̀, Fabio Petroni, Sebastian Riedel, and Marco BaroniICLR, 2023
Can discrete information extraction prompts generalize across language models?Nathanaël Carraz Rakotonirina, Roberto Dessı̀, Fabio Petroni, Sebastian Riedel, and Marco BaroniICLR, 2023We study whether automatically-induced prompts that effectively extract information from a language model can also be used, out-of-the-box, to probe other language models for the same information. After confirming that discrete prompts induced with the AutoPrompt algorithm outperform manual and semi-manual prompts on the slot-filling task, we demonstrate a drop in performance for AutoPrompt prompts learned on a model and tested on another. We introduce a way to induce prompts by mixing language models at training time that results in prompts that generalize well across models. We conduct an extensive analysis of the induced prompts, finding that the more general prompts include a larger proportion of existing English words and have a less order-dependent and more uniform distribution of information across their component tokens. Our work provides preliminary evidence that it’s possible to generate discrete prompts that can be induced once and used with a number of different models, and gives insights on the properties characterizing such prompts.
-
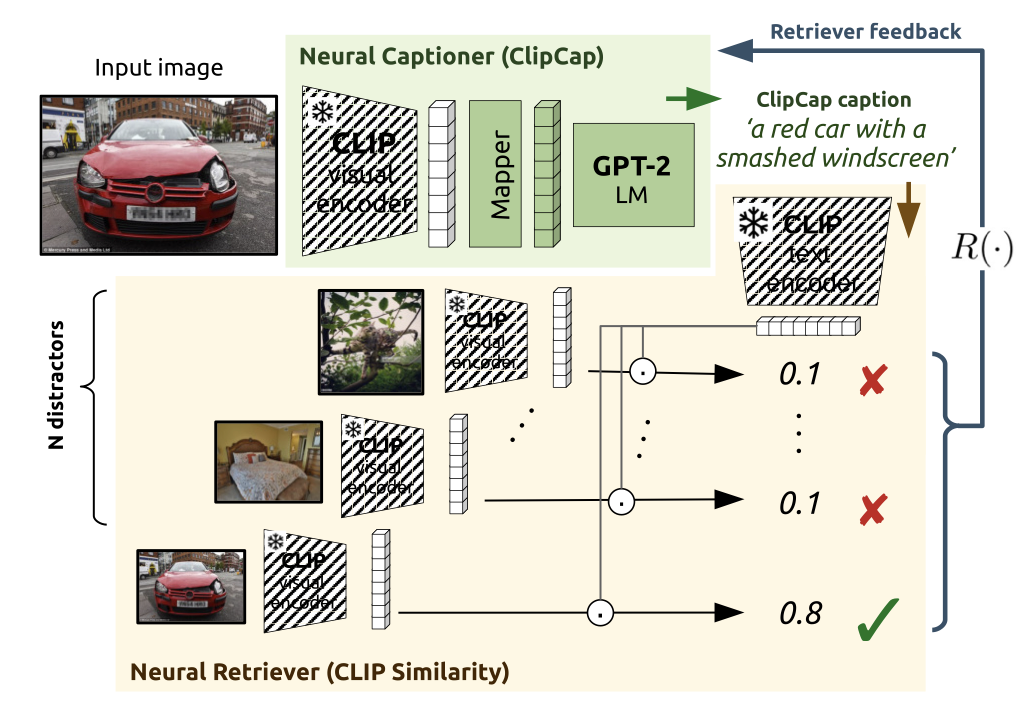 Cross-Domain Image Captioning with Discriminative FinetuningRoberto Dessı̀, Michele Bevilacqua, Eleonora Gualdoni, Nathanaël Carraz Rakotonirina, Francesca Franzon, and Marco BaroniCVPR, 2023
Cross-Domain Image Captioning with Discriminative FinetuningRoberto Dessı̀, Michele Bevilacqua, Eleonora Gualdoni, Nathanaël Carraz Rakotonirina, Francesca Franzon, and Marco BaroniCVPR, 2023Neural captioners are typically trained to mimic human-generated references without optimizing for any specific communication goal, leading to problems such as the generation of vague captions. In this paper, we show that fine-tuning an out-of-the-box neural captioner with a self-supervised discriminative communication objective helps to recover a plain, visually descriptive language that is more informative about image contents. Given a target image, the system must learn to produce a description that enables an out-of-the-box text-conditioned image retriever to identify such image among a set of candidates. We experiment with the popular ClipCap captioner, also replicating the main results with BLIP. In terms of similarity to ground-truth human descriptions, the captions emerging from discriminative finetuning lag slightly behind those generated by the non-finetuned model, when the latter is trained and tested on the same caption dataset. However, when the model is used without further tuning to generate captions for out-of-domain datasets, our discriminatively-finetuned captioner generates descriptions that resemble human references more than those produced by the same captioner without finetuning. We further show that, on the Conceptual Captions dataset, discriminatively finetuned captions are more helpful than either vanilla ClipCap captions or ground-truth captions for human annotators tasked with an image discrimination task.
-
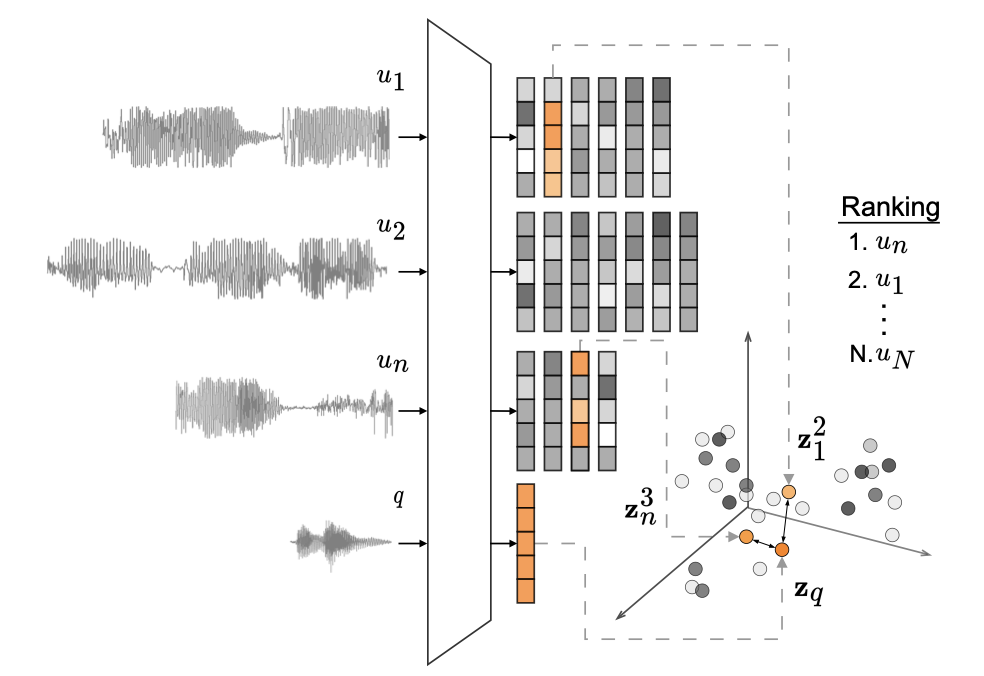 Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and SwahiliChristiaan Jacobs, Nathanaël Carraz Rakotonirina, Everlyn Asiko Chimoto, Bruce A Bassett, and Herman KamperINTERSPEECH, 2023
Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and SwahiliChristiaan Jacobs, Nathanaël Carraz Rakotonirina, Everlyn Asiko Chimoto, Bruce A Bassett, and Herman KamperINTERSPEECH, 2023We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) mod- els that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In con- trast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar perfor- mance to an ASR system trained on 30 hours of labelled data.



2022
- Fairness in generative modeling: do it unsupervised!Mariia Zameshina, Olivier Teytaud, Fabien Teytaud, Vlad Hosu, Nathanaël Carraz Rakotonirina, Laurent Najman, and Markus WagnerGECCO, 2022
We design general-purpose algorithms for addressing fairness issues and mode collapse in generative modeling. More precisely, to design fair algorithms for as many sensitive variables as possible, including variables we might not be aware of, we assume no prior knowledge of sensitive variables: our algorithms use unsupervised fairness only, meaning no information related to the sensitive variables is used for our fairness-improving methods. All images of faces (even generated ones) have been removed to mitigate legal risks.
2021
-
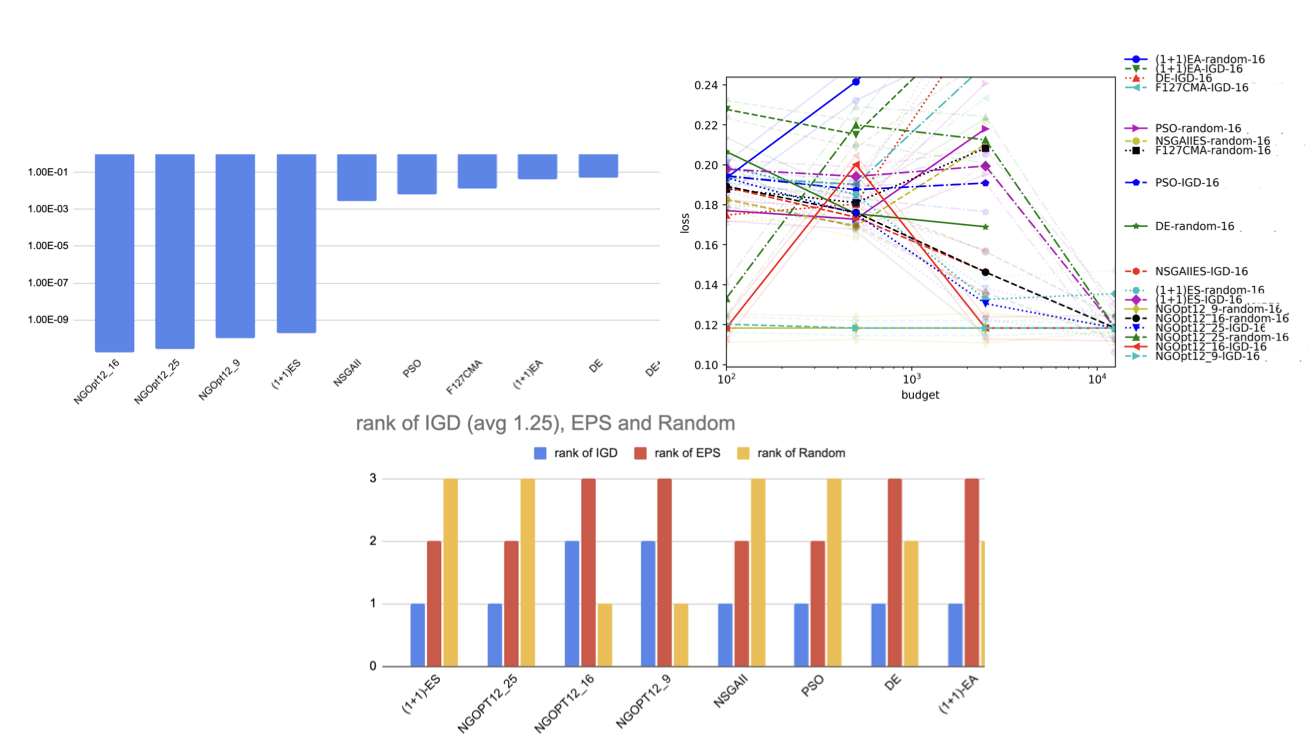 Many-Objective Optimization for Diverse Image GenerationNathanaël Carraz Rakotonirina, Andry Rasoanaivo, Laurent Najman, Petr Kungurtsev, Jeremy Rapin, Fabien Teytaud, Baptiste Roziere, Olivier Teytaud, Markus Wagner, Pak-Kan Wong, and othersArXiv preprint, 2021
Many-Objective Optimization for Diverse Image GenerationNathanaël Carraz Rakotonirina, Andry Rasoanaivo, Laurent Najman, Petr Kungurtsev, Jeremy Rapin, Fabien Teytaud, Baptiste Roziere, Olivier Teytaud, Markus Wagner, Pak-Kan Wong, and othersArXiv preprint, 2021In image generation, where diversity is critical, people can express their preferences by choosing among several proposals. Thus, the image generation system can be refined to satisfy the user’s needs. In this paper, we focus on multi-objective optimization as a tool for proposing diverse solutions. Multiobjective optimization is the area of research that deals with optimizing several objective functions simultaneously. In particular, it provides numerous solutions corresponding to trade-offs between different objective functions. The goal is to have enough diversity and quality to satisfy the user. However, in computer vision, the choice of objective functions is part of the problem: typically, we have several criteria, and their mixture approximates what we need. We propose a criterion for quantifying the performance in multi-objective optimization based on cross-validation: when optimizing n−1 of the n criteria, the Pareto front should include at least one good solution for the removed n th criterion. After providing evidence for the validity and usefulness of the proposed criterion, we show that the diversity provided by multiobjective optimization is helpful in diverse image generation, namely super-resolution and inspirational generation.
-
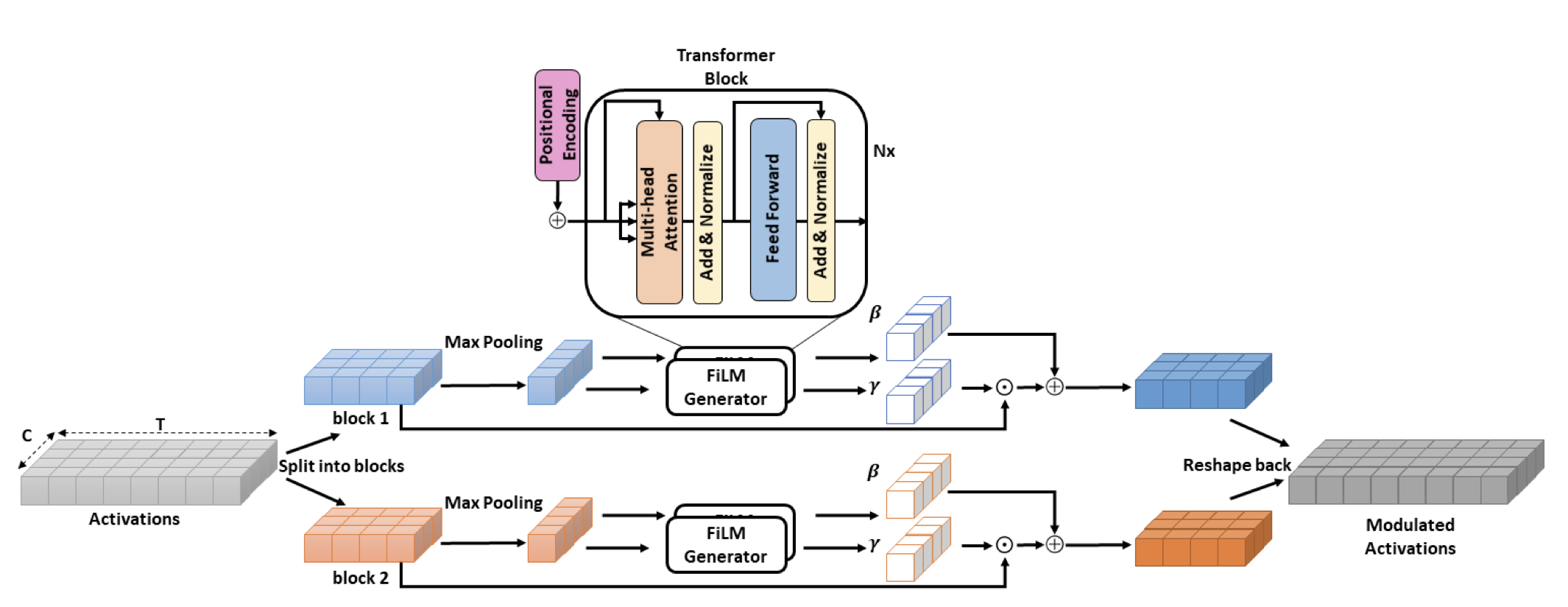 Self-attention for audio super-resolutionNathanaël Carraz RakotonirinaMLSP, 2021
Self-attention for audio super-resolutionNathanaël Carraz RakotonirinaMLSP, 2021Convolutions operate only locally, thus failing to model global interactions. Self-attention is, however, able to learn representations that capture long-range dependencies in se- quences. We propose a network architecture for audio super-resolution that combines convolution and self-attention. Attention-based Feature-Wise Linear Modulation (AFiLM) uses self-attention mechanism instead of recurrent neural net- works to modulate the activations of the convolutional model. Extensive experiments show that our model outperforms existing approaches on standard benchmarks. Moreover, it allows for more parallelization resulting in significantly faster training.
-
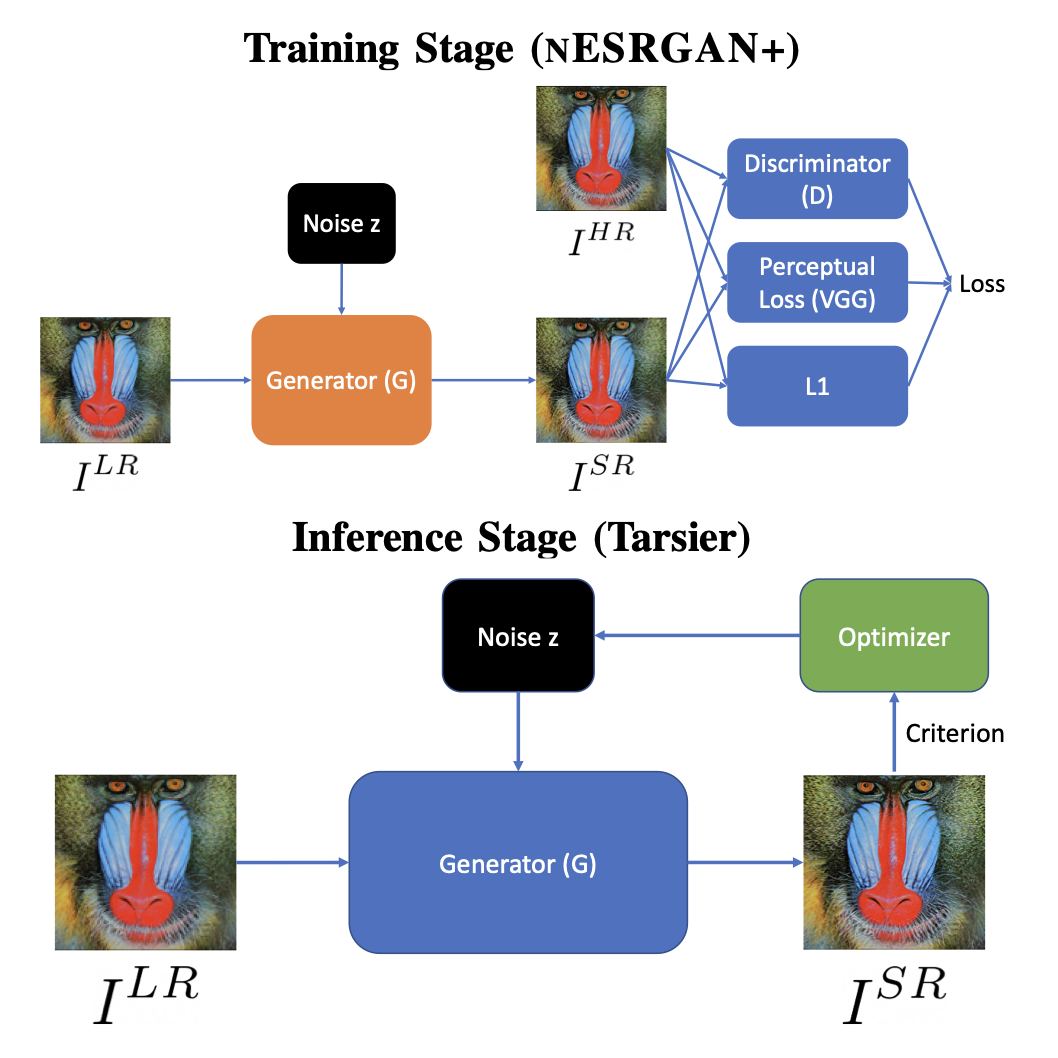 Tarsier: Evolving noise injection in super-resolution gansBaptiste Roziere, Nathanaël Carraz Rakotonirina, Vlad Hosu, Andry Rasoanaivo, Hanhe Lin, Camille Couprie, and Olivier TeytaudICPR, 2021
Tarsier: Evolving noise injection in super-resolution gansBaptiste Roziere, Nathanaël Carraz Rakotonirina, Vlad Hosu, Andry Rasoanaivo, Hanhe Lin, Camille Couprie, and Olivier TeytaudICPR, 2021Super-resolution aims at increasing the resolution and level of detail within an image. The current state of the art in general single-image super-resolution is held by NESRGAN+, which injects a Gaussian noise after each residual layer at training time. In this paper, we harness evolutionary methods to improve NESRGAN+ by optimizing the noise injection at inference time. More precisely, we use Diagonal CMA to optimize the injected noise according to a novel criterion combining quality assessment and realism. Our results are validated by the PIRM perceptual score and a human study. Our method outperforms NESRGAN+ on several standard super-resolution datasets. More generally, our approach can be used to optimize any method based on noise injection.



2020
-
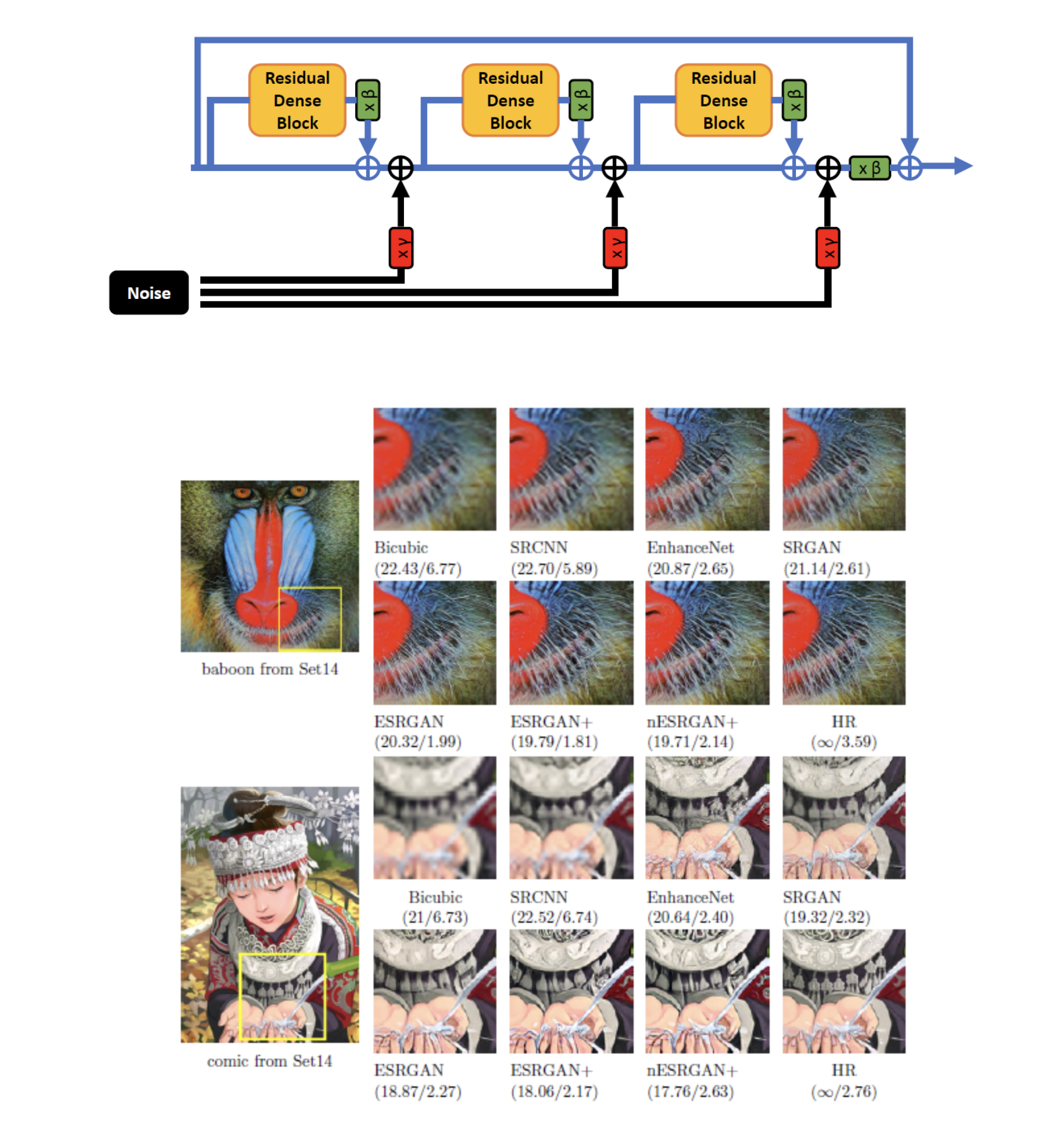 ESRGAN+: Further improving enhanced super-resolution generative adversarial networkNathanaël Carraz Rakotonirina, and Andry RasoanaivoICASSP, 2020
ESRGAN+: Further improving enhanced super-resolution generative adversarial networkNathanaël Carraz Rakotonirina, and Andry RasoanaivoICASSP, 2020Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) is a perceptual-driven approach for single image super-resolution that is able to produce photorealistic images. Despite the visual quality of these generated images, there is still room for improvement. In this fashion, the model is extended to further improve the perceptual quality of the im- ages. We have designed a network architecture with a novel basic block to replace the one used by the original ESRGAN. Moreover, we introduce noise inputs to the generator net- work in order to exploit stochastic variation. The resulting images present more realistic textures.

Teaching
Introduction to Machine Learning
Université d’Antananarivo, MISA
NVIDIA DLI University Ambassador